We will be using the Prompt Learning SDK. You can read our docs page for the SDK at that link.Documentation Index
Fetch the complete documentation index at: https://arize-ax.mintlify.dev/docs/llms.txt
Use this file to discover all available pages before exploring further.
What is Prompt Learning?
Prompt Learning is an algorithm developed by Arize AX to optimize prompts based on data. See our detailed blog on Prompt Learning, and/or a quick summary of the algorithm below..png)
- Build dataset of inputs/queries
- Generate outputs with your unoptimized, base prompt
- Build LLM evals or human annotations to return natural language feedback
- e.g. explanations -> why this output was correct/incorrect (most powerful)
- e.g. confusion reason -> why the model may have been confused
- e.g. improvement suggestions -> where the prompt should be improved based on this input/output pair
- Use meta-prompting to optimize the original prompt
- feed prompt + inputs + outputs + evals + annotations to another LLM
- ask it to generate an optimized prompt!
- Run and evaluate new, optimized prompt with another experiment
Prompt Learning for Structured Output Generation
In this cookbook we use Prompt Learning to improve accuracy of GPT-4o-mini on JSON webpage generation. To view and run the notebook, first clone the Prompt Learning repository.notebooks -> phoenix_support_query_classification.ipynb.
You can see the notebook here. But keep in mind you will have to clone the repository and run the notebook within the notebooks folder for the notebook to run!
Ruleset
We measure accuracy of a prompt based on whether the JSON outputs generated from using the prompt follow a pre-defined set of JSON rules. We have 3 benchmarks - 10 rules, 50 rules, and 100 rules. The more rules the outputs have to follow, the harder we are evaluating the prompt, because we are setting more constraints for its outputs to be correct. An output is only considered “correct” if it meets all the rules within the chosen ruleset. Seeprompts -> JSON_webpage_generation -> evaluator-prompt-{num_rules}.txt to see the differing rulesets.
Dataset Design
The dataset used in this notebook consists of queries that ask a model to generate JSON webpages. Each row includes an input query describing the page that should be built. For eaxample:- NUM_SAMPLES: how many rows to sample from the full dataset
- TRAIN_SPLIT_FRACTION: proportion of rows used for training vs. testing
- NUM_RULES: number of evaluator rules loaded (e.g., 10, 50)
- NUM_OPTIMIZATION_LOOPS: how many iterations of optimization to run
Train/Test Split
To avoid overfitting, we will split our dataset into Train and Test sets. The optimizer will run on the train set, optimizing the prompt based on the input/output/eval pairs from the training set. We will then test each generated prompt on the test set to get an extrapolated estimate of how much our prompt has improved.Base Prompt
We begin with a minimal, unoptimized, baseline system prompt:Evaluators
Evaluators are the core of the feedback loop. They assess the quality of model outputs and provide structured feedback to the optimizer, which drives optimization. Two evaluators are used here:**evaluate_output**— checks if the generated JSON is correct and provides an explanation.**rule_checker**— identifies which specific rules were violated.
Code
Explanation
- Both evaluators use LLM-as-judge: a GPT-4.1 model evaluates outputs instead of humans.
evaluate_outputassigns a binary correct/incorrect label and a natural-language explanation.rule_checkerchecks compliance against the full rule set and outputs detailed violations.- This dual feedback gives both coarse signals (correctness) and fine-grained guidance (specific rules broken).
Optimization Loop
The optimization loop ties everything together. It repeatedly generates outputs, evaluates them, and updates the system prompt using evaluator feedback.NOTE: The code in the notebook implements a few more things, like storing prompts and accuracies. Only the most minimal implementation is shown below for simplicity.
Code
Explanation
- Initial Evaluation: Test the base prompt to establish a starting score.
- Train Evaluation: Generate outputs on the train set and run evaluators to collect correctness, explanations, and rule violations.
- Optimize Prompt: Feed this feedback into the
PromptLearningOptimizerto generate a refined system prompt. - Test Evaluation: Validate the new prompt against the test set.
- Repeat until performance meets the threshold or the maximum number of loops is exhausted.
Results
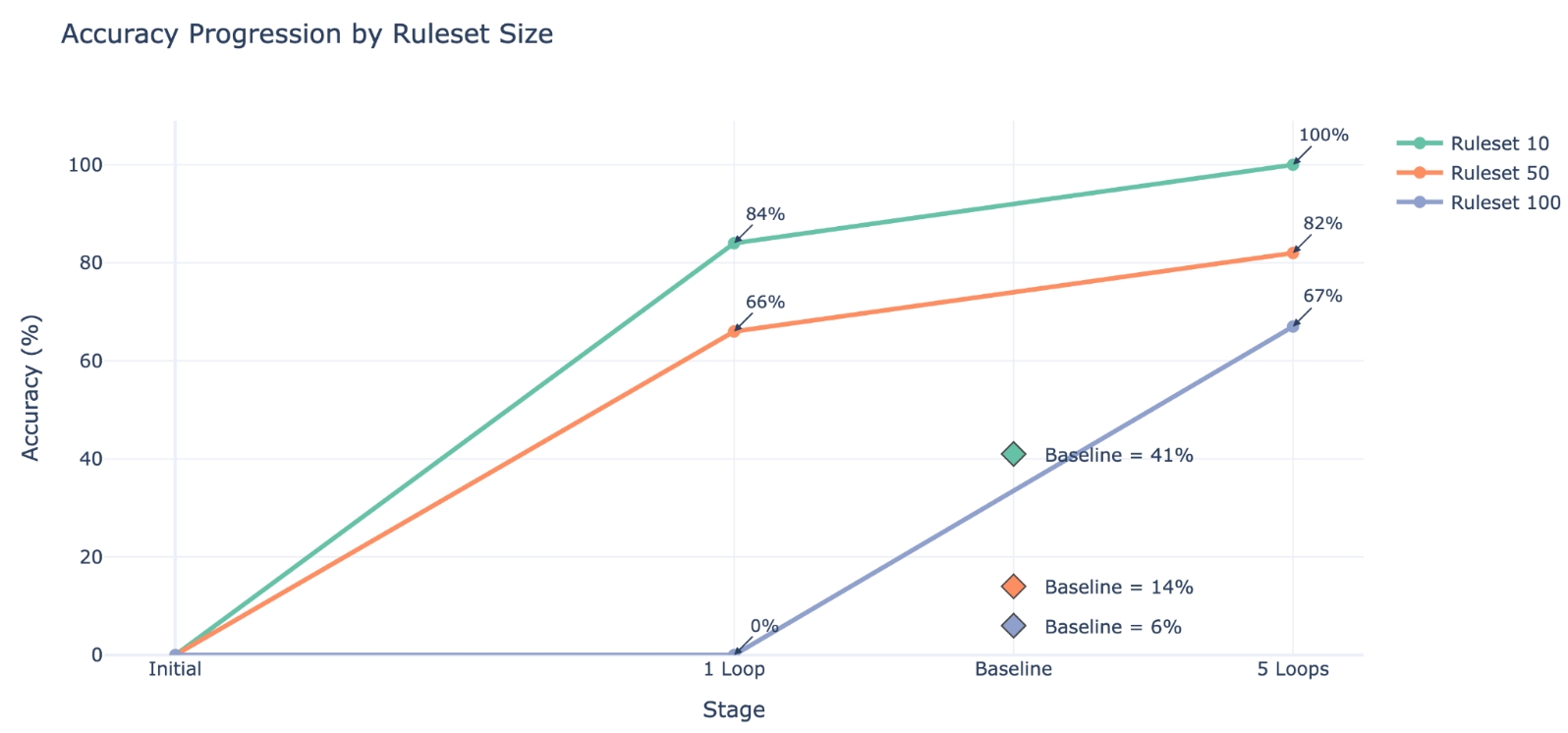
We started off with a prompt that resulted in webpages that didn’t follow any of the rules at all. In just 1 loop -> high accuracies like 84 or 66 based on the number of rules we were checking In just 5 loops -> even higher accuracies. This shows that prompt learning allows LLMs to learn new rules, even up to 50/100 rules for a certain task, when at first it didn’t know any of them.