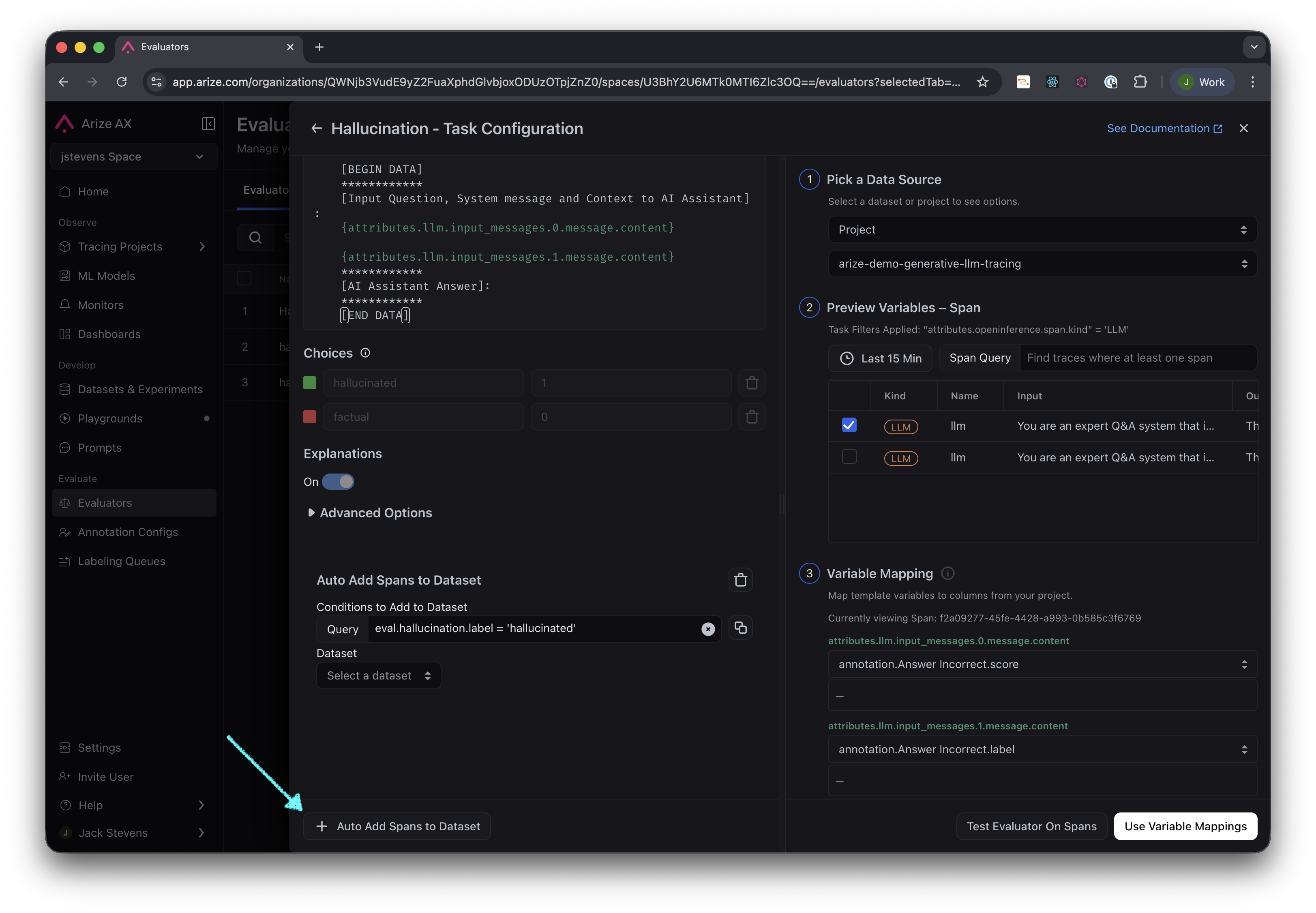
Curate dataset from evaluation labels
After setting up an evaluation task on a project, you can include a post-processing step that automatically adds examples to a dataset based on the evaluation label. First you need to edit the configuration of the Evaluator for your task:
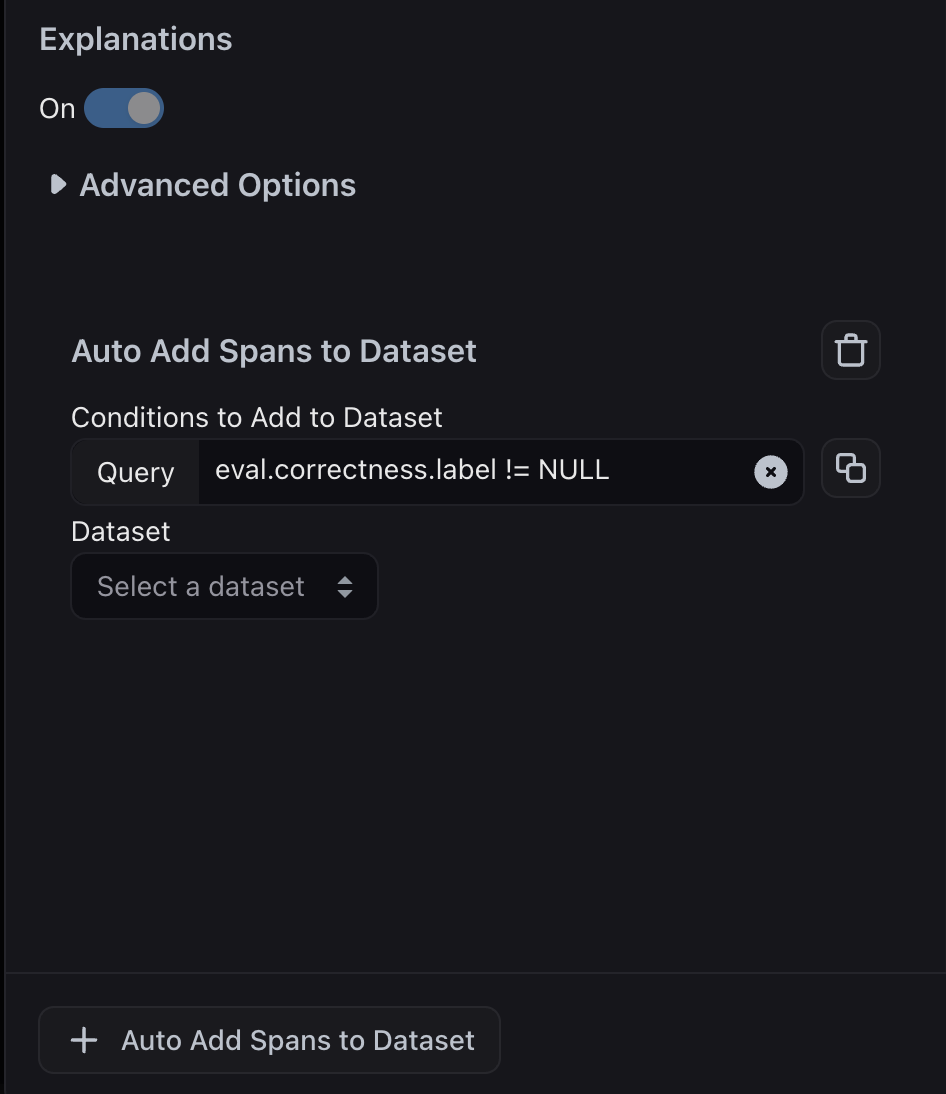
Curate dataset from filters
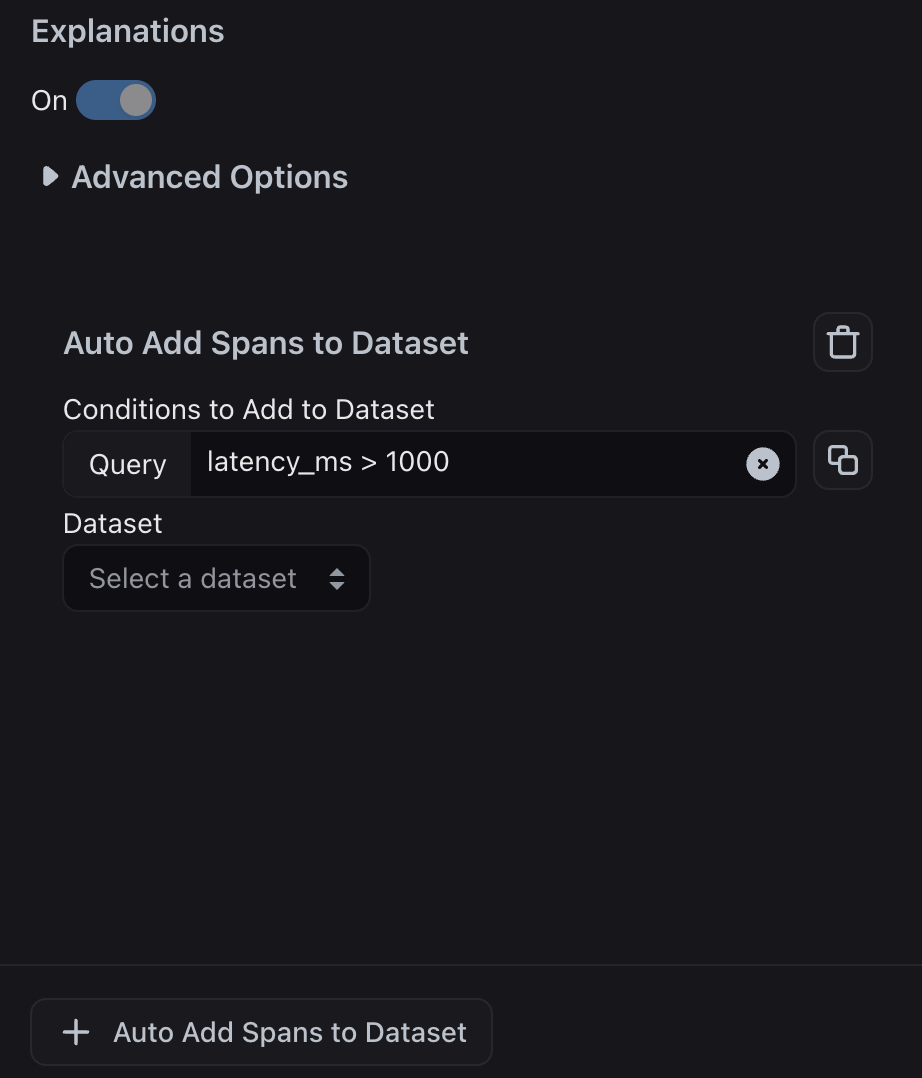
Alternatively, instead of using an evaluation label, you can add any example to a dataset that meets basic filter criteria, such as high token count in the LLM output, high latency, or examples where a specific tool was called.