Documentation Index
Fetch the complete documentation index at: https://arize-ax.mintlify.dev/docs/llms.txt
Use this file to discover all available pages before exploring further.
Build Arize-Powered Tooling in Go with the New Go SDK v2
May 13, 2026 New SDKs and REST APIs The first release of the Arize Go SDK v2 (client-go-v2 v0.1.0) is now available, so you can integrate Arize directly into Go services and pipelines.
- Core client —
arize.NewClientwires HTTP transport, headers, and configuration with environment-variable overrides and secret masking. - Resource resolution — Look up spaces, projects, datasets, experiments, prompts, evaluators, annotation configs, annotation queues, AI integrations, and tasks by name or ID.
- Typed errors and pre-release guardrails — Structured HTTP error types with
Unwrapsupport, plus one-time warnings on alpha/beta endpoints so you know exactly which surfaces are stable.
Automatically Add Spans to Labeling Queues
May 13, 2026 New Annotations You can now configure a labeling queue to automatically pull in spans matching optional filter criteria, so you can build review pipelines without manual curation.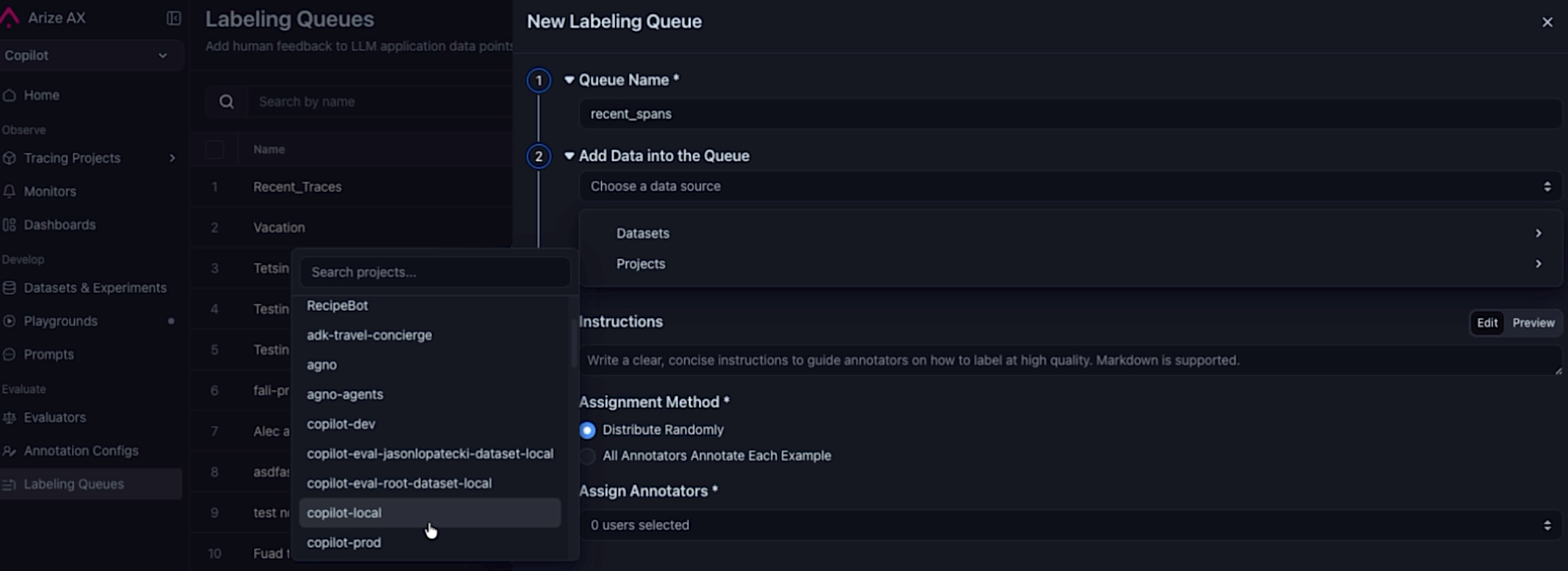 Selecting a project as the datasource when creating a queue to automatically pull in spans.
Selecting a project as the datasource when creating a queue to automatically pull in spans.
- Project datasource — Select a project as the data source when creating a queue.
- Query filter — Optionally scope which spans are routed for labeling (for example,
attributes.openinference.span.kind = 'LLM'). - Sampling rate — Route a representative slice of traffic when matching span volume exceeds annotation bandwidth.
- Continuous and backfill modes — Enable continuous ingestion to keep pace with new traffic, backfill to seed the queue from existing spans, or both.
- Queue cap — Set an optional cap to prevent unbounded growth and keep the queue manageable.
Run an Evaluator on Selected Experiments in One Click
May 13, 2026 Improvement Datasets and Experiments Pick experiments in the Experiments table, click Run Evaluator, and the evaluator creation dialog opens with those experiments already pre-populated. No need to re-select them by hand.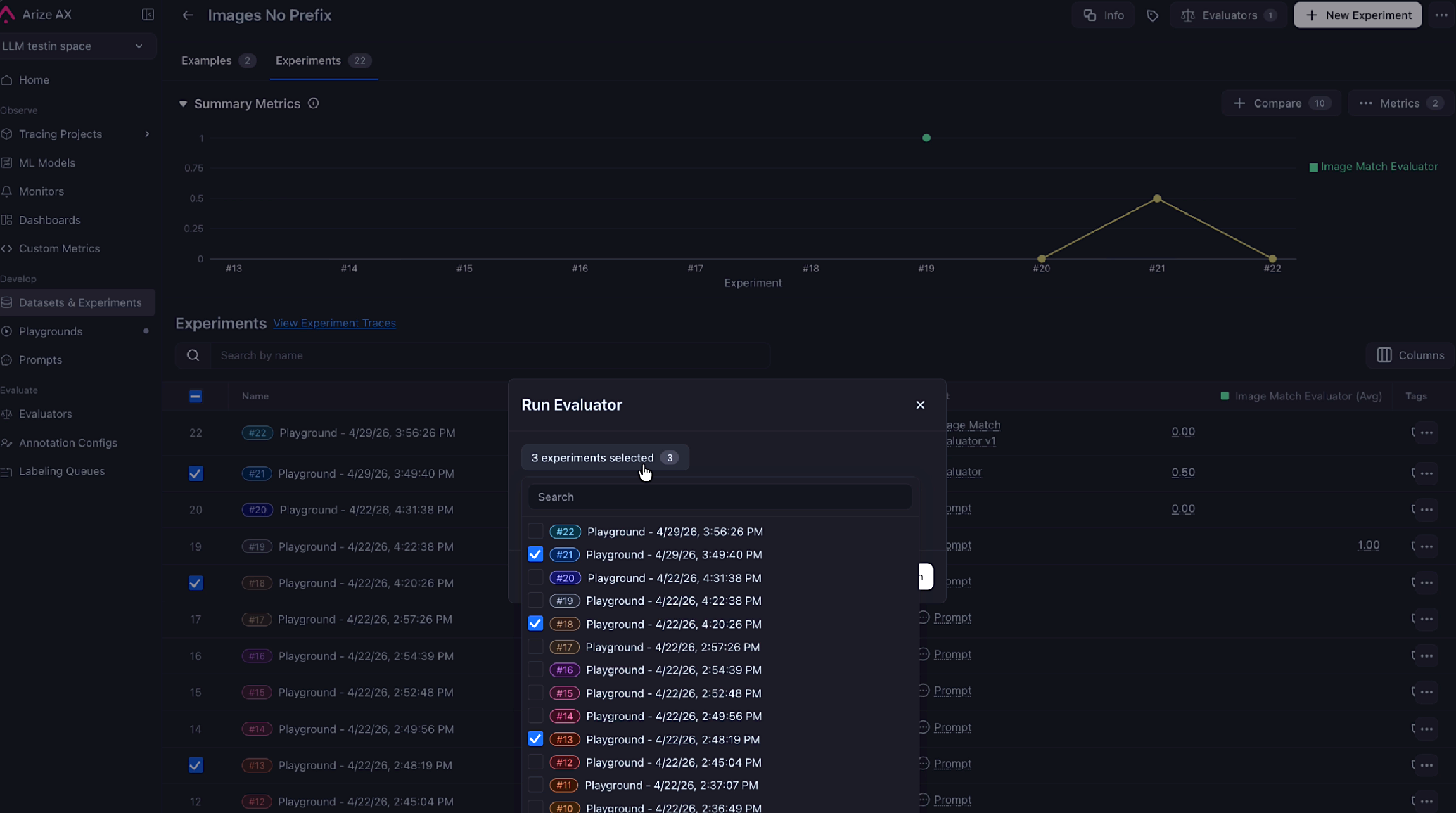 Selected experiments are now pre-populated in the evaluator dialog.
For more information, refer to the run offline evals on experiments documentation.
Selected experiments are now pre-populated in the evaluator dialog.
For more information, refer to the run offline evals on experiments documentation.
Manage Users, Roles, and Invitations from the Python SDK
May 12, 2026 New SDKs and REST APIsarize-python-sdk v8.24.0 adds full CRUD support for the /v2/users endpoints so you can manage your account’s user base programmatically instead of clicking through the UI.
- Lifecycle operations —
users.list(),get(),create(),update(), anddelete()cover the standard CRUD flow. - Invitation and password flows —
users.resend_invitation()andusers.reset_password()automate the most common admin chores. - Typed domain models — User, organization, and space roles now return as Pydantic models with discriminated unions, so
ax users listand other CLI surfaces produce cleanto_dfoutput instead of crashing on raw API types.
Fixes and Improvements
May 7–13, 2026 Custom Metrics- Improvement
PROJECTis now accepted as an alias forMODELin custom metric SQL, so you can writeFROM projectto match how tracing projects are named elsewhere in the platform. ExistingFROM modelqueries are unaffected.
- Improvement The Alyx home agent can now list traces directly, so you can ask for recent traces without having to switch surfaces first.
- Fix Editing a Prompt Playground prompt through Alyx no longer fails when the model returns the prompt as a JSON-encoded string—Alyx parses it automatically and retries less often.
- Fix The Alyx
read_prompttool validates prompt IDs before calling, eliminating a class of failed reads. - Fix Re-opening an Alyx chat with a
custom_trace_viewwidget no longer renders a fresh Accept button, so users can’t accidentally create duplicate views.
- Improvement A new background job soft-deletes annotation queue records that have been annotated or sat untouched for a year, keeping queue tables from growing unbounded as the auto-add-to-queue feature ramps up.
- Fix Creating an annotation queue via
POST /v2/annotation-queuesno longer throws 500 errors for accounts whose user names aren’t"admin"—the underlying SQL now references the correct column.
- Fix Toggling Enable Tracing on an existing template-eval online task now persists on save. Previously the field was silently dropped when patching legacy (pre–Eval Hub) tasks, so tracing reverted on reload.
- Improvement The integration setup flow now shows tooltips on each field, so it’s easier to understand what each value should be before submitting.
- Fix
POST /v2/experimentsnow returns400 Bad Requestfor schema mismatches such as aneval.*.scoretype mismatch, instead of a generic500.
- Fix Switching to pretty JSON formatting in the trace view no longer causes UI issues on large payloads.
Visualize Evaluator Score Distributions Across Spans and Experiments
May 6, 2026 New Dashboards and Visualizations Eval score charts are now available to all users. Visualize how your evaluator scores distribute across spans and experiments directly from the model overview and tracing pages—no configuration required.Review and Confirm Alyx Proposals Before They Take Effect
May 6, 2026 Improvement Alyx Three Alyx operations that previously applied changes silently now go through a visible confirmation drawer before taking effect. You can review, edit, and accept or skip each proposal before it is saved.- Eval Form Proposals: When Alyx suggests creating or updating an evaluator, it now shows an editable drawer with the proposed name, display name, template, and classification choices. Edit any field before accepting.
- Task Creation: Alyx surfaces a review drawer when proposing a new evaluation task, showing the task name, evaluator, target project or dataset, run mode, and sampling rate before the task is created.
- Task Configuration: Configuring task parameters through Alyx now always routes through a confirmation drawer, whether you’re on the task-builder page or elsewhere in the platform.
Control Annotation Queue Capacity with Per-Queue Record Limits
May 6, 2026 Improvement Annotations You can now set and clear a custommax_records cap on individual annotation queues from the queue settings UI. A per-queue limit overrides the global account default, so high-volume queues and targeted review queues can each hold the right number of records without a one-size-fits-all ceiling.
Assign Multiple Annotation Queue Records to a Reviewer in Bulk
May 6, 2026 New Annotations Assign multiple annotation queue records to a reviewer in a single operation. Select the records you want to route, choose a reviewer, and submit—no need to assign them one at a time.Wire Experiment Runs into Automated Pipelines with the run_experiment REST API
May 6, 2026 New SDKs and REST APIs The v2 REST API now supports experiment run tasks. You can create, update, and triggerrun_experiment tasks programmatically with the same endpoints used for other task types, making it straightforward to wire experiment runs into automated pipelines.
Fixes and Improvements
May 1–6, 2026- Fix Models and Integrations Azure OpenAI o-family models (o1, o3-mini, o4-mini) now work correctly in Prompt Playground and evals—the default API version is updated to
2025-04-01-previewso you no longer need to enter it manually. - Fix Datasets and Experiments The “View Experiment Traces” button now returns correct results for experiments run via the Arize Python SDK, which uses
experiment_idrather thandataset_id. - Fix Evaluators Eval result columns in
eval.<name>.<field>format generated by AX experiment evals are no longer dropped before the output is returned. - Fix Evaluators “View Task Logs” from an eval feedback tooltip now opens the exact task run instead of an approximate lookup that failed for renamed evaluators and older runs.